Vous l’ aurez probablement lu ou entendu dans les médias ces derniers jours : les Institutions Européennes ont trouvé un accord sur la future réglementation de l’ Intelligence Artificielle ce vendredi 8 décembre. C’ est le fameux European Artificial Intelligence Act dont j’ avais déjà esquissé les grandes lignes dans un article précédent.
A l’ époque, je n’ avais pas parlé de la réglementation des modèles généralistes car ce point restait en discussion. Il est maintenant temps de pallier à cette omission.
Ce qui suit se base sur les informations disponibles 48 heures après l’ accord. Le texte détaillé de l’ accord n’est pas encore connu; il devrait être publié avant le 22 janvier, date du premier comité parlementaire à son sujet. Mon but n’ est cependant pas d’ aller dans le détail mais juste de vous donner un aperçu de l’ approche retenue.
1. Pourquoi l’ IA généraliste complique la réglementation
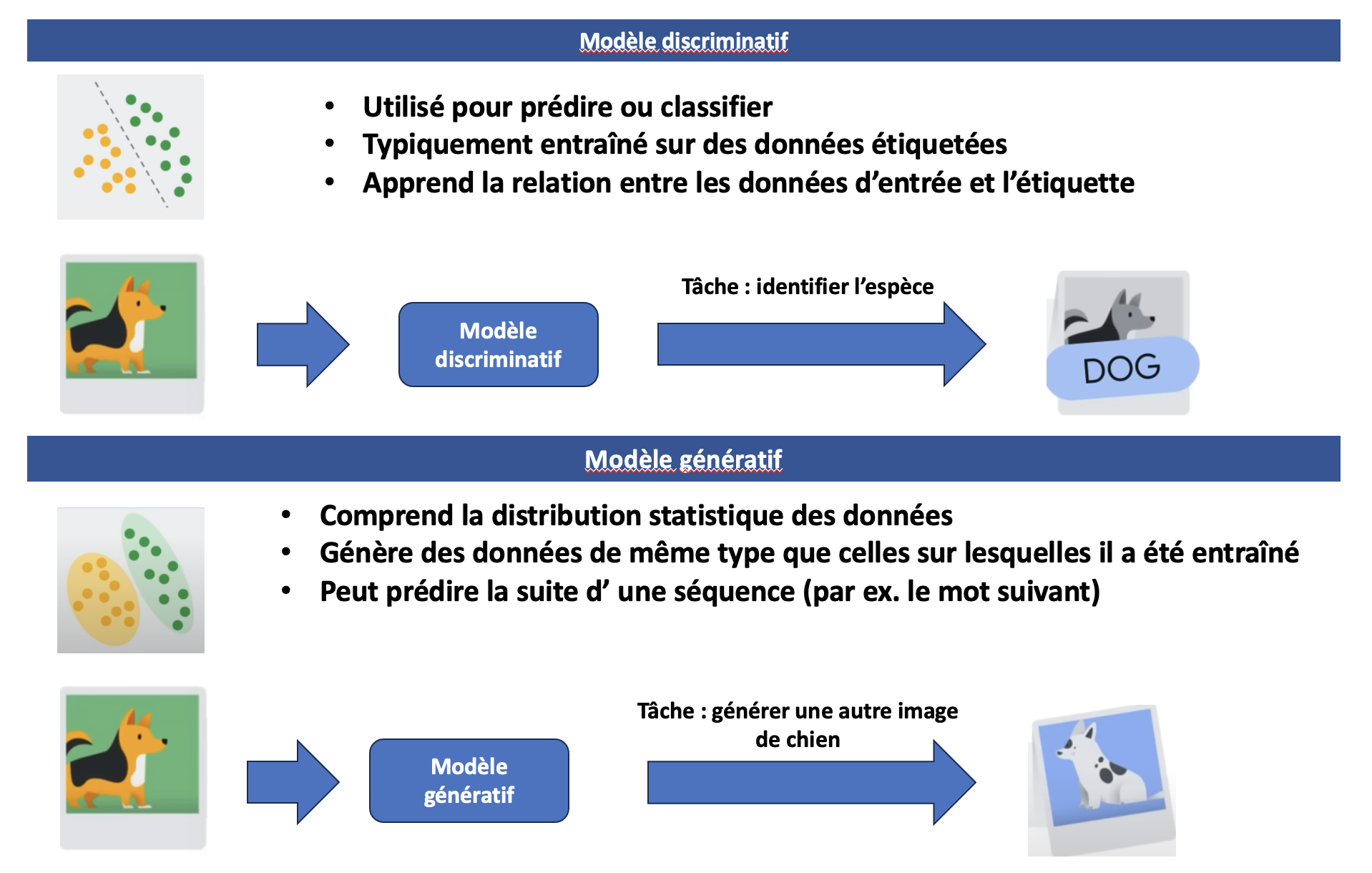
Les modèles IA généralistes sont apparus il y a quelques années. On les définit en fonction de la modalité qu’ ils traitent (texte, image, vidéo, 3D...) et de leur nature discriminative ou générative.
Ces modèles se caractérisent par un large spectre d’ applications, et leur grand avantage est de pouvoir être affinés pour réaliser avec précision un tâche spécialisée. Cet affinage peut être réalisé par une autre entreprise disposant de moyens bien inférieurs à ceux nécessaires à l’ entraînement du modèle de base. Un modèle textuel génératif comme GPT3 peut donc être adapté pour réaliser différentes tâches dans différents secteurs (par exemple des chatbots pour du service à la clientèle).
Dès lors, la chaîne de valeur de l’ IA généraliste peut mettre en jeu plusieurs acteurs : un acteur en amont qui développe un modèle généraliste puissant et le met à disposition d’ acteurs en aval qui vont affiner et exploiter le modèle pour le mettre à leur tour sur le marché à destination des utilisateurs finaux.
Cette multiplication des acteurs ne s’ intègre pas bien dans la logique de l’ EU AI Act qui se base sur le risque pour l’ utilisateur final. Cette logique est appropriée pour une application IA développée par une organisation dans un but spécifique, mais si l’ on applique cette logique à l’ IA généraliste seuls les acteurs en aval seront directement sujets à la réglementation. La réglementation de l’ acteur en amont ne se fera qu’ indirectement par « percolation » des exigences posées sur les acteurs en aval. Pas très équilibré si vous êtes une petite start-up qui exploite un modèle développé par Google ou OpenAI… et vu le rôle techniquement central de l’ acteur amont, les risques ne sont pas réglementés à leur source.
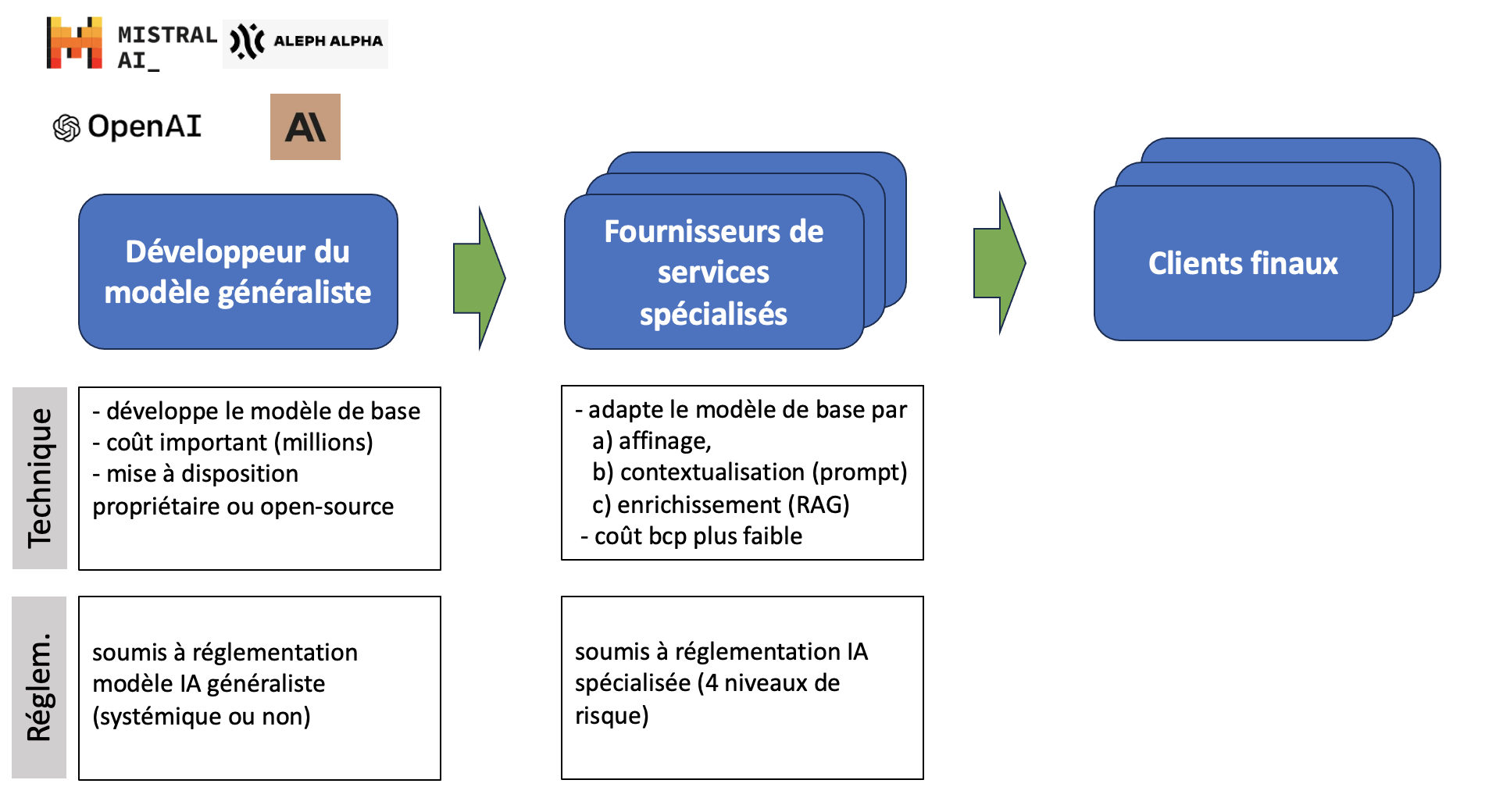
Il a donc fallu définir une réglementation différente pour l’ IA généraliste. Celle-ci va s’ appliquer spécifiquement à l’ acteur amont. Ceci ne dédouane pas entièrement l’ acteur aval qui reste soumis aux contraintes réglementaires basées sur le risque utilisateur, mais ce dernier peut au moins se reposer sur la conformité du modèle généraliste sur lequel il se base.
2. Réglementation de l’ IA généraliste
Cette réglementation fait la distinction entre deux catégories de modèles sur base de leur puissance : les modèles les plus capables sont appelés « systémiques » par opposition aux autres.
Tous les modèles généralistes sont soumis à des exigences de transparence : ils doivent documenter en détail l’architecture du modèle ainsi que le jeu de données qui a servi à son entraînement, et confirmer le respect des droits d’auteur. Le contenu généré par un modèle génératif devra être reconnaissable comme tel.
De plus, les modèles considérés « systémiques » vont êtres soumis à des exigences supplémentaires : leurs créateurs devront mener à bien des évaluations du modèle, démontrer comment ils gèrent et mitigent les risques, notifier les autorités en cas d’ incident et démontrer leur résilience face aux cyberattaques.
Les modèles généralistes open-source bénéficieront d’ une réglementation allégée (au moins pour les non-systémiques), mais la nature de cet allègement n’ est pas encore claire.
Toutes ces exigences seront détaillées et précisées à travers des standards européens harmonisés qui seront établis par des organismes comme le comité IA du CEN/CENELEC, une fois l’ Acte voté.
3. Notes et références
- Communiqué de presse du Conseil de l’ Union Européenne du 9 décembre 2023 : https://www.consilium.europa.eu/en/press/press-releases/2023/12/09/artificial-intelligence-act-council-and-parliament-strike-a-deal-on-the-first-worldwide-rules-for-ai/
- Communiqué de presse du Parlement Européen du 9 décembre 2023 : https://www.europarl.europa.eu/news/en/press-room/20231206IPR15699/artificial-intelligence-act-deal-on-comprehensive-rules-for-trustworthy-ai
- Vidéo officielle de la conférence de presse du 8 décembre 2023 : https://video.consilium.europa.eu/event/en/27283
- European Union squares the circle on the wold’s first AI rulebook, par Luca Bertuzzi (Euractiv) le 9 décembre 2023 : https://www.euractiv.com/section/artificial-intelligence/news/european-union-squares-the-circle-on-the-worlds-first-ai-rulebook/
- AI Act : EU policymakers nail down rules on AI models, butt heads on law enforcement, par Luca Bertuzzi ( Euractiv), le 7 décembre 2023 : https://www.euractiv.com/section/artificial-intelligence/news/ai-act-eu-policymakers-nail-down-rules-on-ai-models-butt-heads-on-law-enforcement/
